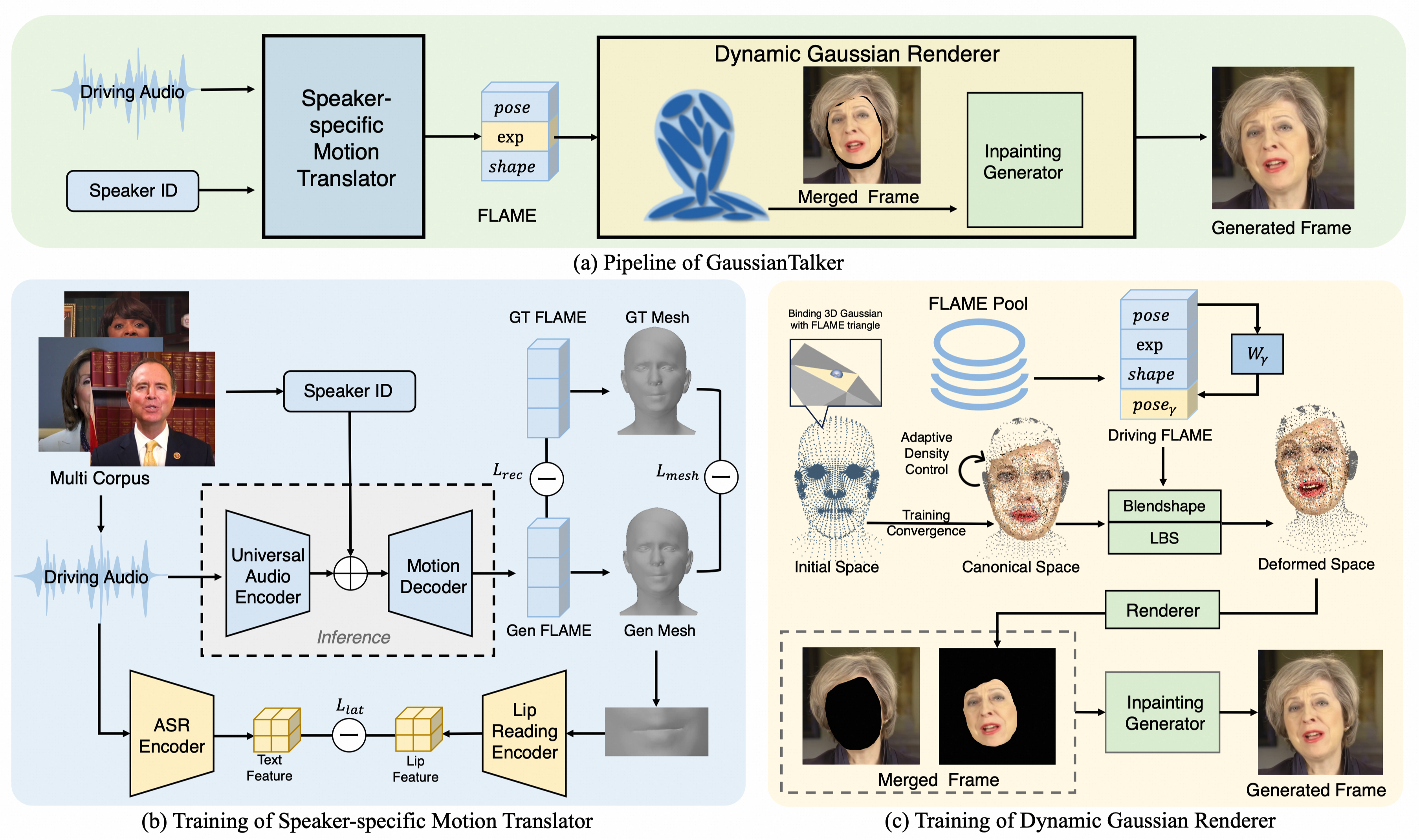
Recent work on audio-driven talking head synthesis using neural radiation fields (NeRF) has achieved impressive results. However, due to inadequate posture and expression control caused by NeRF implicit representation, these methods still have some limitations, such as unsynchronized or unnatural lip movements, and visual jitter and artifacts. In this paper, we propose GaussianTalker, a novel method for audio-driven talking head synthesis based on 3D Gaussian Splatting. With the explicit representation property of 3D Gaussians, intuitive control of the facial motion is achieved by binding Gaussians to 3D facial models. GaussianTalker consists of two modules, Speaker-specific Motion Translator and Dynamic Gaussian Renderer. The Speaker-specific Motion Translator achieves accurate lip movements specific to the target speaker through universalized audio feature extraction and customized lip motion generation. The Dynamic Gaussian Renderer introduces Learnable FLAME Embedding for optimizing facial parameters and employs Speaker-specific Blendshapes to enhance facial detail representation via a potential pose, addressing potential issues of visual jitter and artifacts. Extensive experimental results suggest that GaussianTalker outperforms existing state-of-the-art methods in talking head synthesis, delivering precise lip synchronization and exceptional visual quality. Our method achieves rendering speeds of 130 FPS on NVIDIA GPU, significantly exceeding the threshold for real-time rendering performance, and can potentially be deployed on other hardware platforms.